NewClaim a free social report


X analytics
Similar Accounts:
X analytics
Similar Accounts:
followers
9.11K
impressions
1.70M
likes
17.3K
comments
1.04K
posts
585
engagement
1.08%
emv
$39.7K
Average per post
2.91K
Key Metrics
Impressions
monthly
Distributions
Content
98.3K
800
23
93
2mo ago
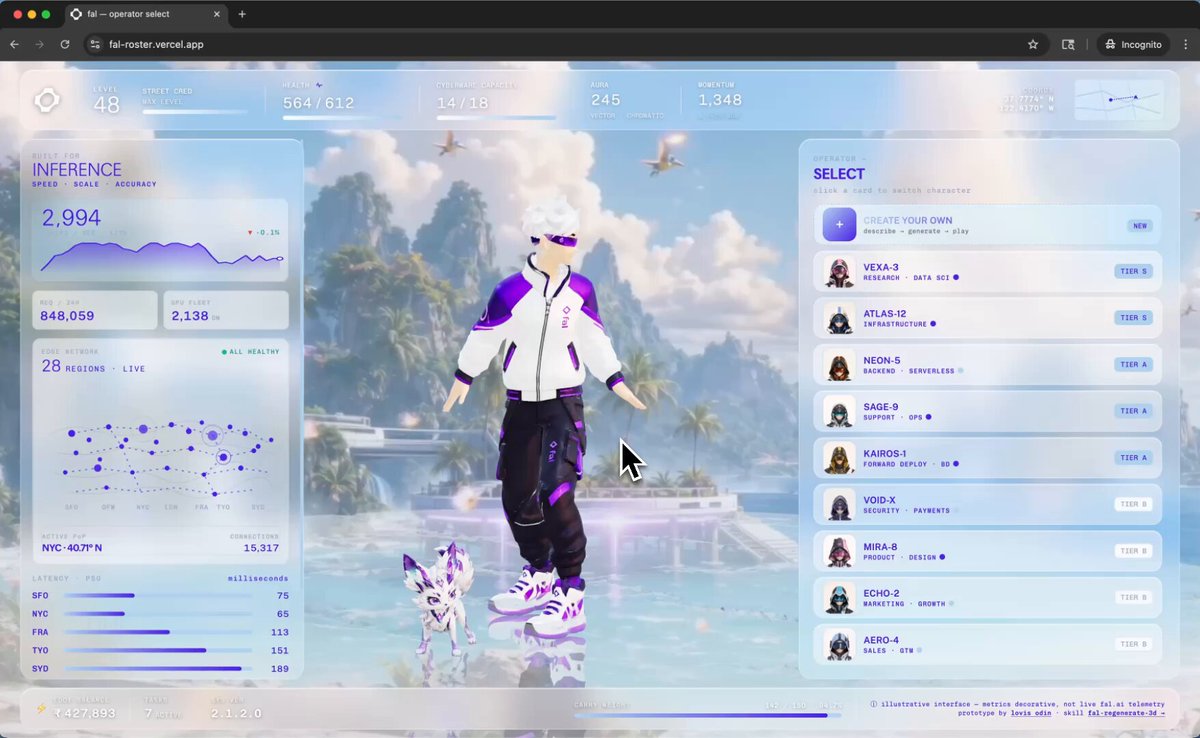
OdinLovis
https://t.co/KVqsD0qo2C , webgl experience
fully made using @fal
the pipeline:
GPT-Image-2 (or FLUX.2 Klein 9B for the live "create your own")
🦴 meshy v6 image-to-3d takes that → rigged GLB with a baked animation
🐾 GPT-Image-2/edit on the same character → companion creature image, color-locked to the character's palette → meshy v6 again (no rig) → static creature GLB
🪨 PATINA (fal-ai/patina/material/extract) takes the character image and outputs basecolor + normal + roughness + metalness for a per-character floor that matches their environment
🎬 Seedance 2.0 fast → 8s looping background video per character
📦 everything runs through gltf-transform (resize 1024 → webp q80 → draco) for ~95% size reduction → 400-800 KB GLBs
🖥️ the front-end is a single static index.html: Three.js scene, alpha-mapped marble disc with PlaneGeometry tessellation for real displacementMap depth, mirrored reflection plane, breathing animations on companions, palette-swap via CSS custom properties on character click
🧩 the whole recipe is published as a Claude Code skill fal-regenerate-3d so you can rebuild this yourself
→ https://t.co/fWDc4ES7si
⚠ metrics shown are decorative
@czoob3 Prefer awaking at 5 am and be done at 7 or 8 max. Your production between 6 to 10 pm is probably 10 times slower than after a good times of sleep.. and people the next day just look dead..
93.9K
59
3
0
7mo ago
OdinLovis
@czoob3 Prefer awaking at 5 am and be done at 7 or 8 max. Your production between 6 to 10 pm is probably 10 times slower than after a good times of sleep.. and people the next day just look dead..
66.9K
749
30
112
9mo ago
OdinLovis
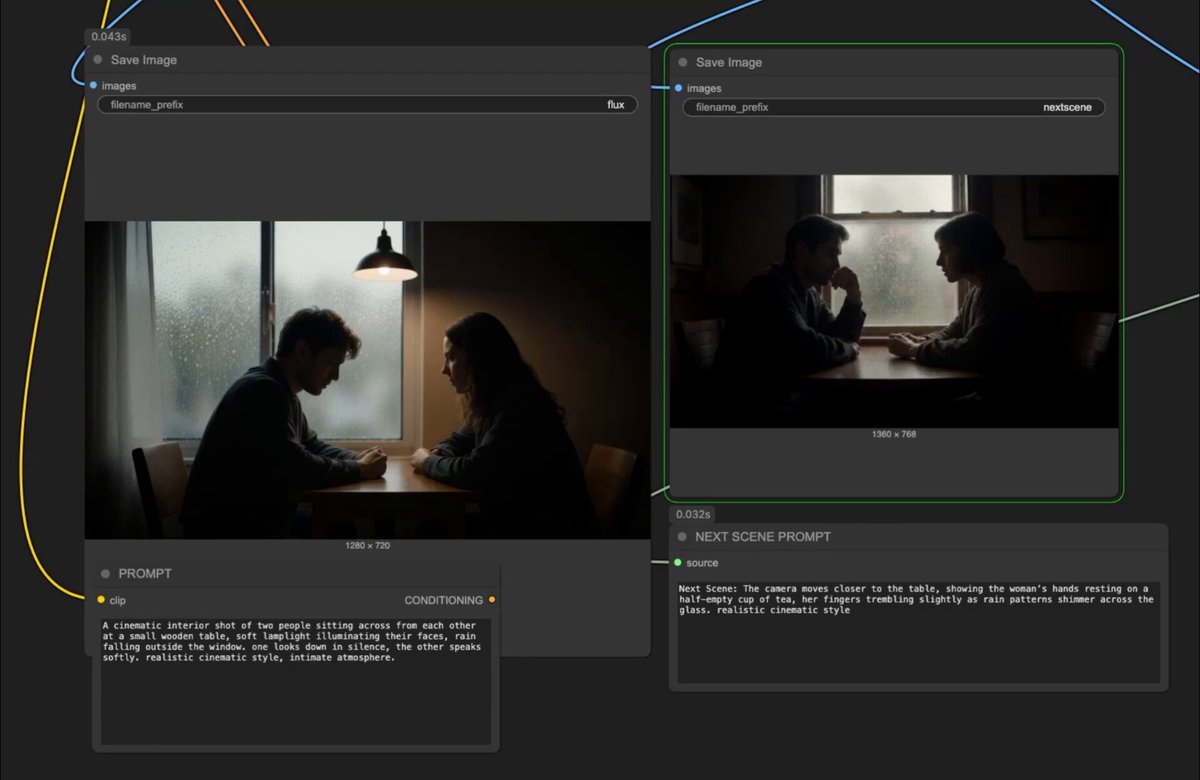
👉 https://t.co/NbjAWj64DB
I created « Next Scene » for Qwen Image Edit 2509 and you can make next scenes keeping character, lighting, environment . And it’s totally open-source ( no restrictions !! )
Just use the prompt « Next scene: » and explain what you want.
I trained it on hundreds of paired shots to preserve characters, lighting, and mood between scenes. ( Soon I will explain what tools I created that can manage classification and caption of data when you have more than 10 000 of items, using workers and a total new way to classify data ) .
Built for storytellers working with ComfyUI or other diffusers pipe ;) !
@ComfyUI

65.7K
1.14K
44
112
4mo ago
OdinLovis
To celebrate nano-banana-2 launching on @fal , I built FalSprite, sprite sheet generator that turns a text prompt into game-ready animations.
One https://t.co/SpUceQWzbJ key powers the whole pipeline:
→ nano-banana-2 for image generation
→ BRIA for background removal
→ OpenRouter LLM for prompt rewriting
~$0.20 per generation. Try it live or fork it:
🔗 https://t.co/GAbZTKokVG
🔗 https://t.co/jLQoHGg8Sq
Thanks @BlendiByl for the help on this 🙏
58.8K
776
33
68
10mo ago
OdinLovis
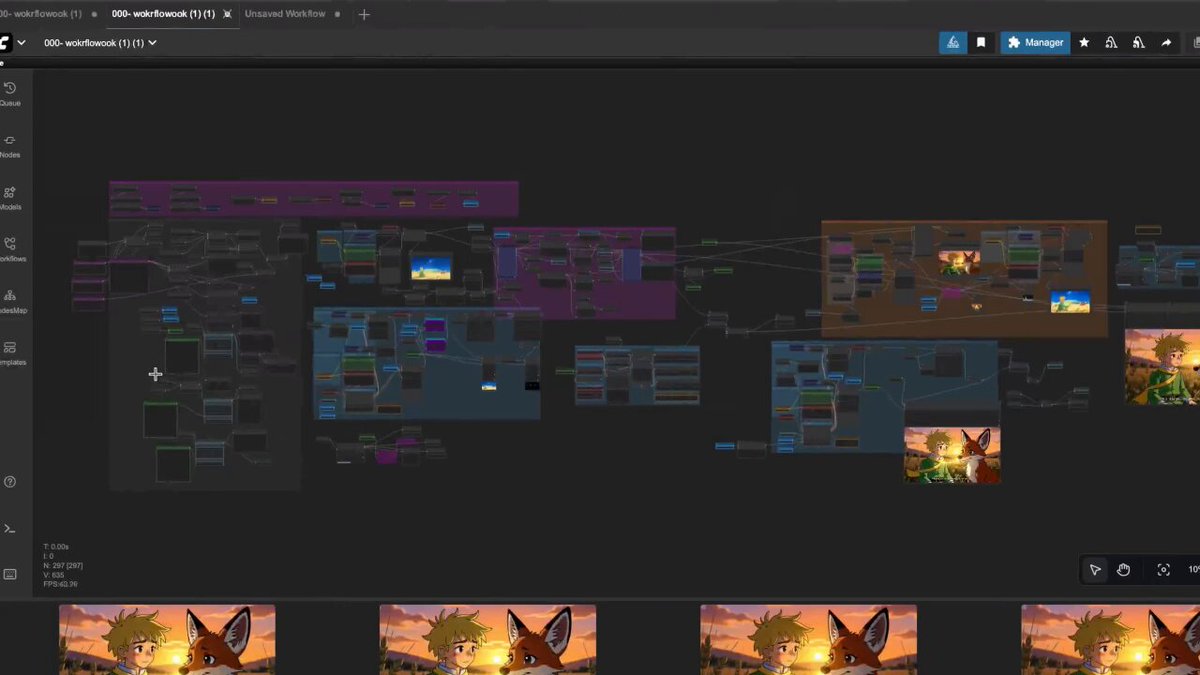
This is probably the most complex workflow I’ve ever built, only with open-source tools. It took my 4 days.
It takes four inputs: author, title, and style; and generates a full visual animated story in one click in @ComfyUI . I worked on it for four days. There are still some bugs, but here’s the first preview.
Here’s a quick breakdown:
- The four inputs are sent to LLMs with precise instructions to generate: first, prompts for images and image modifications; second, prompts for animations; third, prompts for generating music.
- All voices are generated from the text and timed precisely, as they determine the length of each animation segment.
- The first image and video are generated to serve as the title, but also as the guide for all other images created for the video.
- Titles and subtitles are also added automatically in Comfy.
- I also developed a lot of custom nodes for minor frame calculations, mostly to match audio and video.
- The full system is a large loop that, for each line of text, generates an image and then a video from that image. The loop was the hardest part to build in this workflow, so it can process either a 20-second video or a 2-minute video with the same input.
- There are multiple combinations of LLMs that try to understand the text in the best way to provide the best prompts for images and video.
- The final video is assembled entirely within ComfyUI.
- The music is generated based on the LLM output and matches the exact timing of the full animation.
- Done!
For reference, this workflow uses a lot of models and only works on an RTX 6000 Pro with plenty of RAM.
My goal is not to replace humans, as I’ll try to explain later, this workflow is highly controlled and can be adapted or reworked at any point by real artists! My aim was to create a tool that can animate text in one go, allowing the AI some freedom while keeping a strict flow.
I don’t know yet how I’ll share this workflow with people, I still need to polish it properly, but maybe through Patreon.
Anyway, I hope you enjoy my research, and let’s always keep pushing further! :)

58.7K
927
35
76
3w ago
OdinLovis
Its coming tomorrow and no, its not seedance :), it should follow and respect much more the 3d input render, and its gonna be open source !
50.4K
289
20
39
5mo ago
OdinLovis
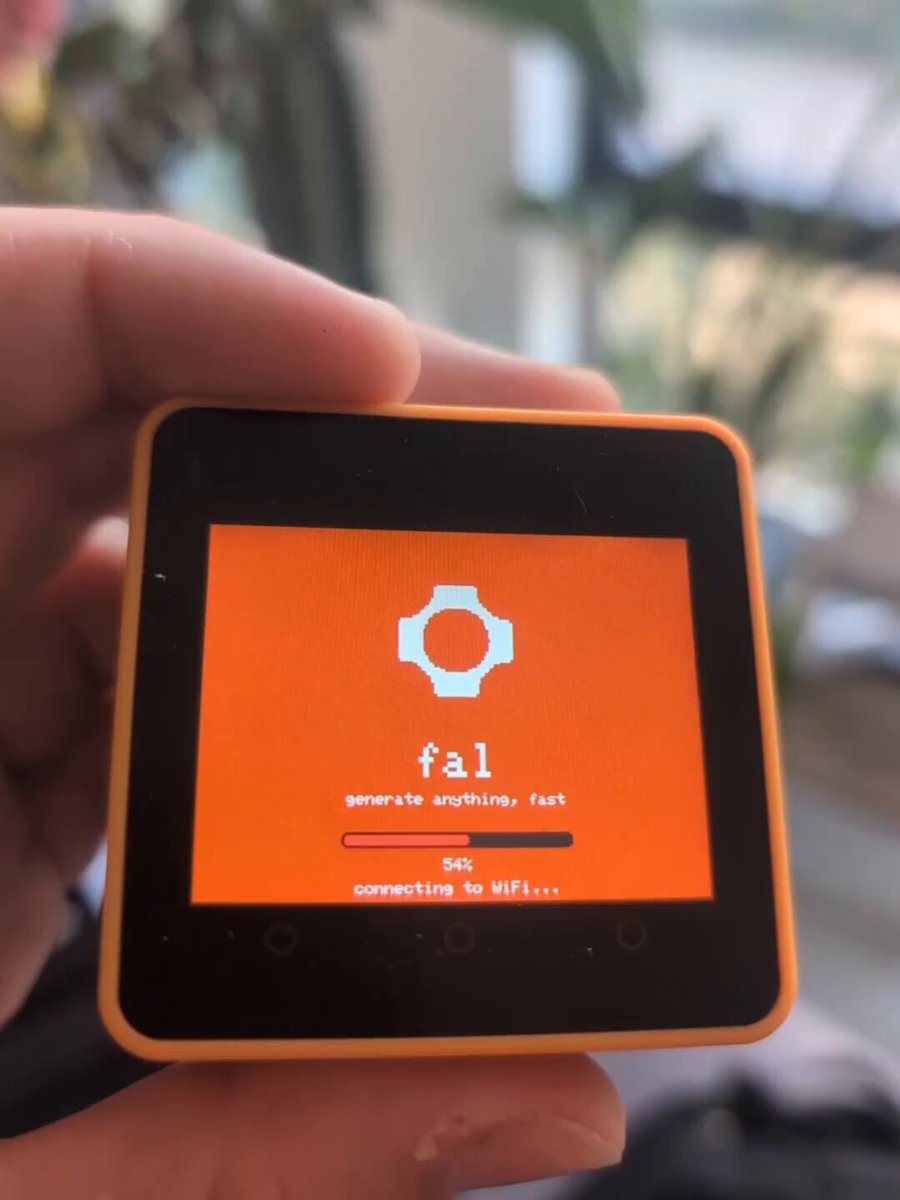
I built a bot on an ESP32 that can create full projects by itself. Ask it to generate images, videos, 3D, build a website and publish it, it does everything autonomously.
Powered by Claude Opus 4.6 for code, visual content generated with @fal, bot powered via @openclaw
The skills to generate project with fal are here https://t.co/6vupJNNVjQ
All running on a tiny M5Stack Core2.
44.6K
443
15
42
2w ago
OdinLovis
Single prompt using Fable in Blender.. Soon result with our new version of the model 3dToReal on @fal
43.8K
598
33
81
7mo ago
OdinLovis
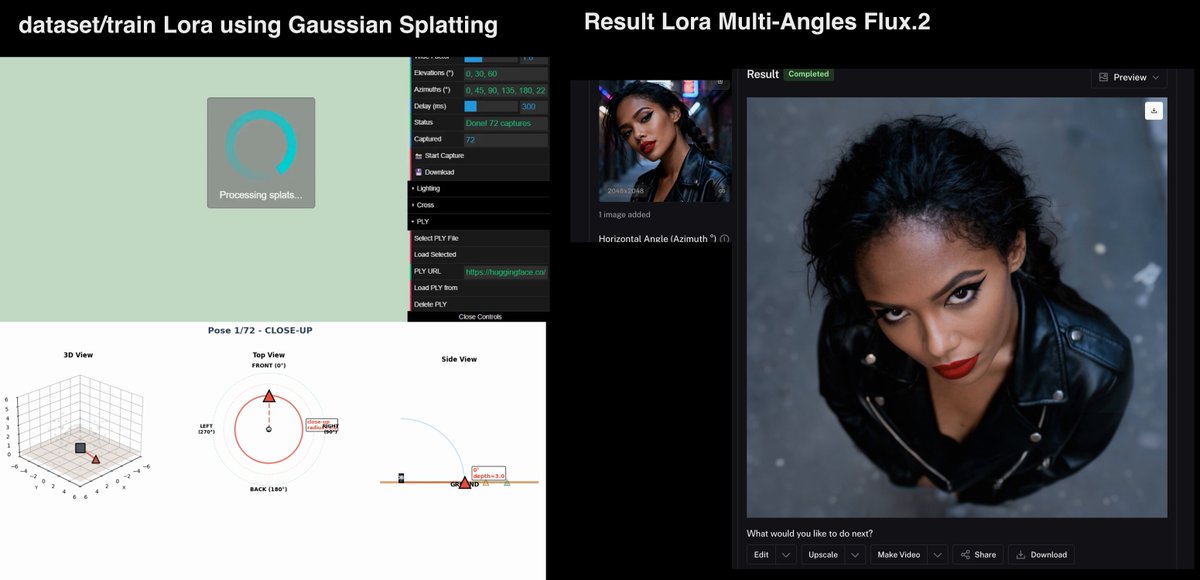
New open source LoRA Multi-Angles I created with @fal for Flux.2 🔥
Flux2.-Lora-Multi-Angles: give a camera angle in degrees → get your image from that view.
To build this, I created a system that captures 72 positions from Gaussian Splatting to generate the training dataset fully automatically in a webgl viewer.
▶️ Test: https://t.co/6lWL2TJy5r
📥 Weights: https://t.co/YUV6CrA2yv
Should I open source my WebGL viewer so you can train your own from gaussian splatting ?
43.3K
422
20
71
9mo ago
OdinLovis
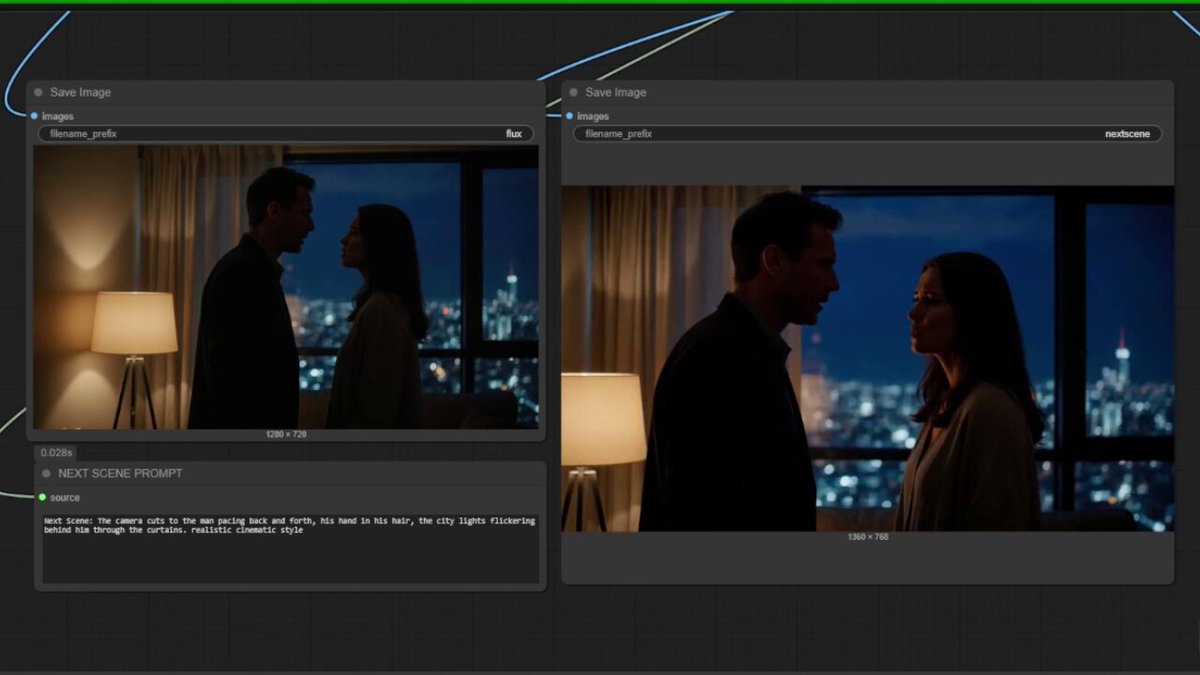
🚀 Update Next Scene V2 only 10 days after last version, now live on Hugging Face
👉 https://t.co/NbjAWj5wO3
🎬 A LoRA made for Qwen Image Edit 2509 that lets you create seamless cinematic “next shots” — keeping the same characters, lighting, and mood.
I trained this new version on thousands of paired cinematic shots to make scene transitions smoother, more emotional, and real.
🧠 What’s new:
• Much stronger consistency across shots
• Better lighting and character preservation
• Smoother transitions and framing logic
• No more black bar artifacts
Built for storytellers using @ComfyUI or any diffusers pipeline.
Just use “Next Scene:” and describe what happens next , the model keeps everything coherent.
🧩 Try it directly in ComfyUI, or check the thread to launch it on @fal .
Open-source, no restrictions, made for filmmakers, animators, and dreamers.
@ComfyUI #AIcinema #LoRA #Flux #Qwen #ComfyUI #AIart #GenerativeVideo
you can test on comfyui or to try on https://t.co/SpUceQW1mb, you can go here :
https://t.co/K3amauYhT2
and use my lora link :
https://t.co/Vp8bBEr5Ol
start your prompt with "Next Scene:" and lets go !!

41.8K
864
45
83
3mo ago
OdinLovis
None of the video gen models do a real CRT terminal animation look.
So I trained my own with @fal.
CRT-anim : open-source LoRA for LTX-2.3 22B. Runs on fal + ComfyUI.
35.0K
429
29
44
6mo ago
OdinLovis
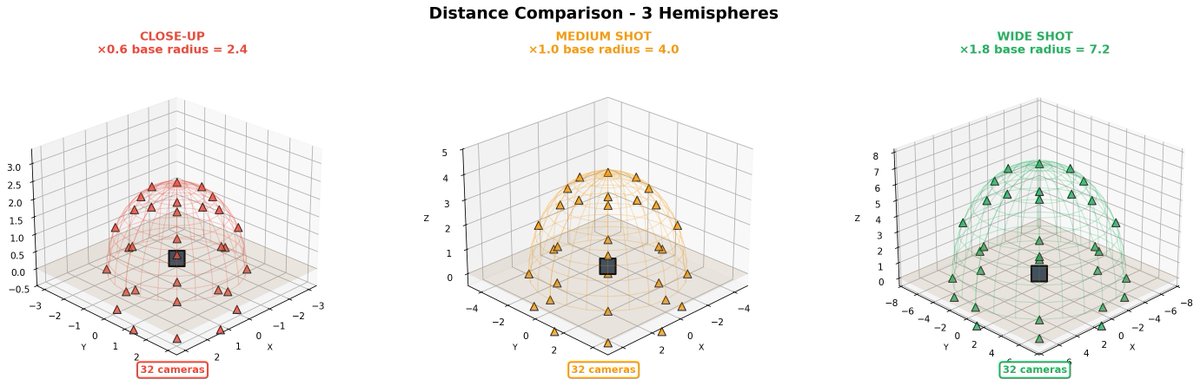
Really proud of this one, I worked hard with @fal to make this the most precise multi-angle LoRA possible.
96 camera poses, 3000+ training pairs from Gaussian Splatting, and full low-angle support.
Open source !
you can run it on fal here :
https://t.co/whvNYb1AQE
and you can also find the lora on hugging face that you can use on comfyui or other (workflow included) :
https://t.co/CX0CYHIdYM
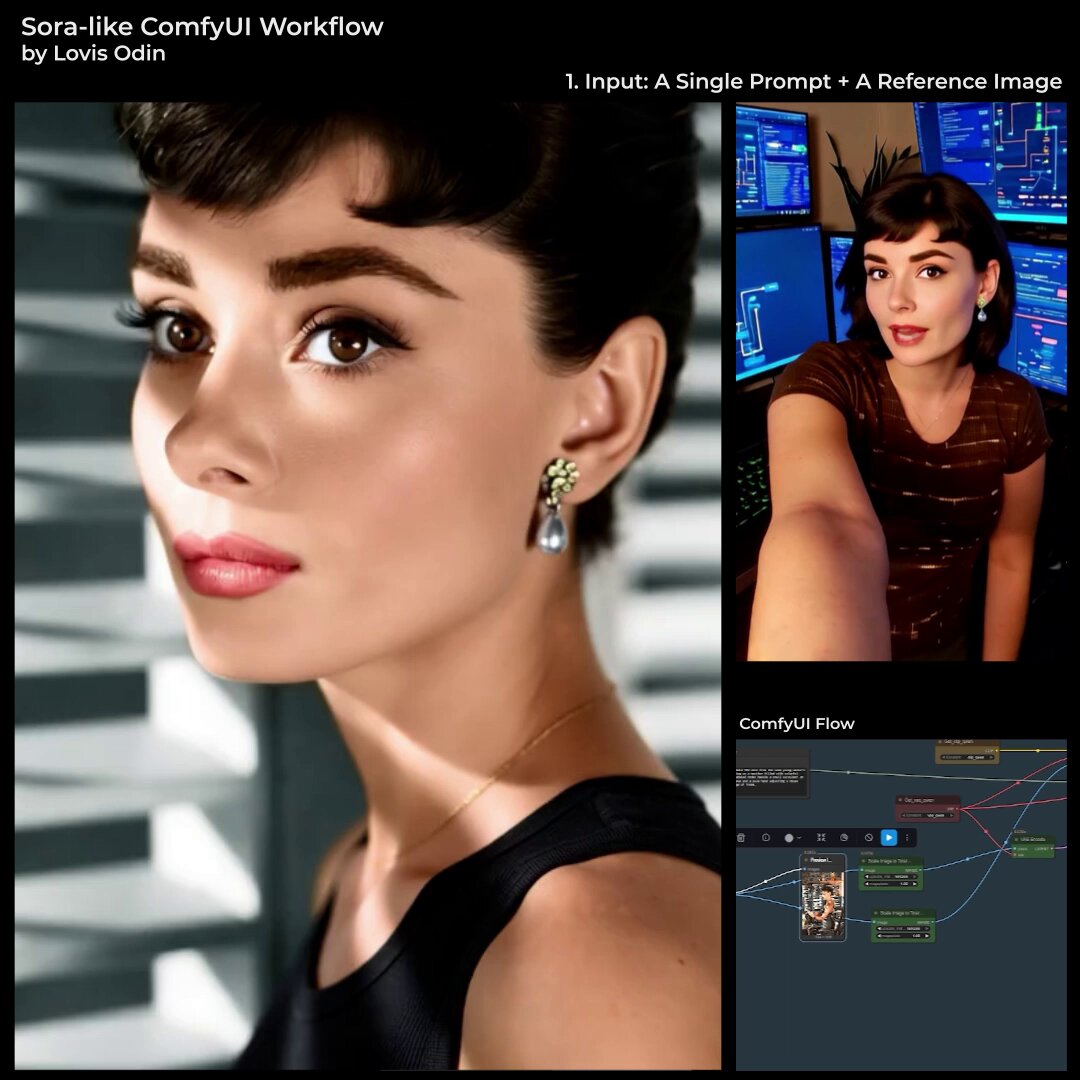
33.8K
344
12
40
9mo ago
OdinLovis
I built a Sora 2-inspired video pipeline in ComfyUI and you can download it !
Technical approach:
→ 4 LLMs pre-process everything (dialogue, shot composition, animation direction, voice profile)
→ Scene 1: Generate image with Qwen-Image → automated face swap (reference photo) → synthesize audio → measure exact duration → animate with Wan 2.2 I2V + Infinite Talk (duration matches audio perfectly)
→ Loop (Scenes 2-N): Take last frame of previous video → edit with Qwen-Image-Edit + "Next Scene" LoRA (changes camera angle while preserving character, that I trained) → automated face swap again → generate audio → measure duration → animate for exact timing → repeat
→ Final: Concatenate all video segments with synchronized audio
Not perfect, needs RTX 6000 Pro, but it's a working pipeline.
Bonus: Also includes my Story Creator workflow (shared a few days ago) — same approach but generates complete narratives with synchronized music + animated text overlays with fade effects.
You can find both workflows here:
https://t.co/1QiCT41Eva
@ComfyUI @OpenAI

33.3K
478
19
70
9mo ago
OdinLovis
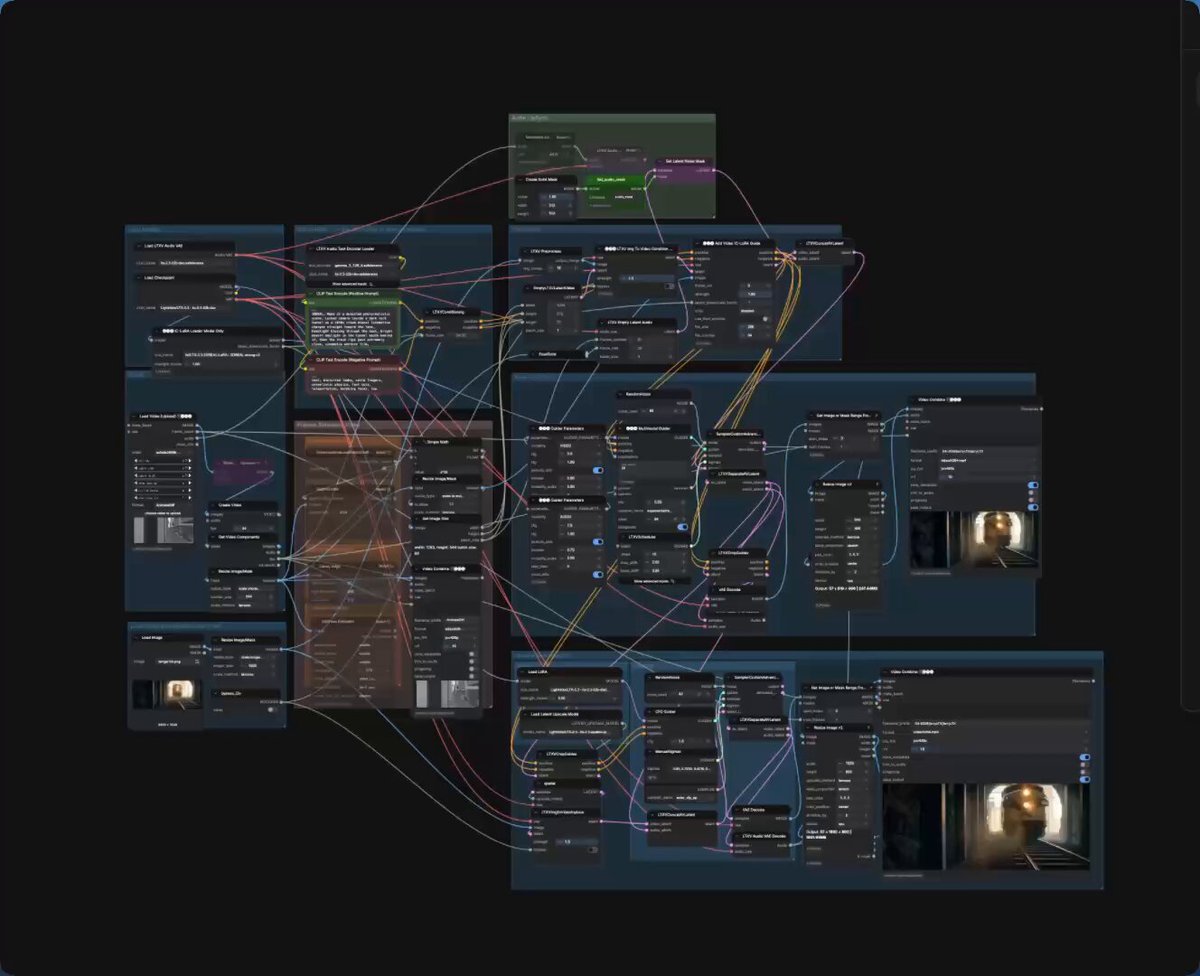
📦 : https://t.co/PitUxvUQBe
I di this ComfyUI workflow for Sora 2 upscaling 🚀 ( or any videos )
Progressive magnification + WAN model = crisp 720p output from low-res videos using Llm and Wan
Built on cseti007's workflow as base (https://t.co/eWQeyyKoKb).
Open source ⭐
It does not work super good at keeping always consistent face for now
More detail about it soon :)
30.2K
507
19
53
7mo ago
OdinLovis
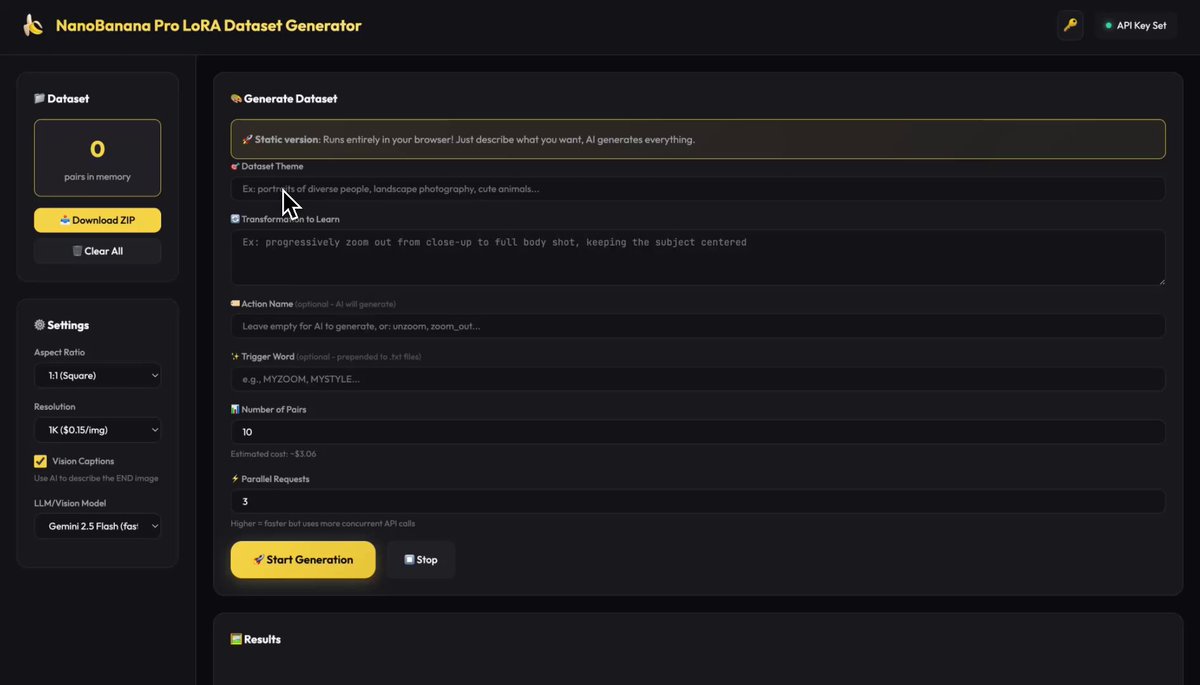
🍌 Just released NanoBanana Pro LoRA Dataset Generator with @fal
Finally an easy way to create training datasets for:
• Flux 2
• Z-Image
• Qwen Image Edit
• Any image-to-image model
✨ Uses Nano Banana Pro API on @fal
🌐 100% browser-based - no server needed
⚡ Parallel generation for speed
🔗 Try it live: https://t.co/6ZqotEYhQz
💻 Code: https://t.co/Ko9Zn19eUD
29.6K
652
11
83
1w ago
OdinLovis
I made the workflow for comfyui to use Ltx 2.3 render to real Ic-lora !
If you want to go fast you can just use our endpoint :
https://fal.ai/models/fal-ai/ltx-2.3-quality/render-to-real
workflow available here :
https://huggingface.co/fal/LTX-2.3-3DREAL-LoRA/tree/main/workflows

24.8K
398
10
75
1w ago
OdinLovis
I just released 3DREAL Strong V2 with @fal : our LoRA for LTX 2.3 that turns a blocky 3D render into photoreal footage, keeping the exact camera, layout and timing.
Fable + Blender + fal ltx 2.3 render-to-real
Weights opensource: http://huggingface.co/fal/LTX-2.3-3DREAL-LoRA
Live endpoint : http://fal.ai/models/fal-ai/ltx-2.3-quality/render-to-real
Full tutorial, all three prompts included: https://blog.fal.ai/from-clay-3d-render-to-a-real-action-short-a-3d-to-ai-pipeline-with-total-control/

22.0K
135
6
18
6mo ago
OdinLovis
Old Art to full 3D using Cinema 4D .
Created a free and open-source plugin to bring Hunyuan 3D directly into Cinema 4D.
https://t.co/9ygbOtmzPW
This workflow combines multiple tools that are available today into a single, cohesive pipeline. I wanted to show that AI is never an end product by itself, it’s not the finality. Used properly, AI becomes an extremely powerful tool that lets you build exactly what you want.
I hope you like it.
The final step will be to bake all textures so I can share the project as a WebGL experience, a small interactive website to explore it directly in the browser.
Made with heart, and with @fal ❤️
21.9K
283
8
25
7mo ago
OdinLovis
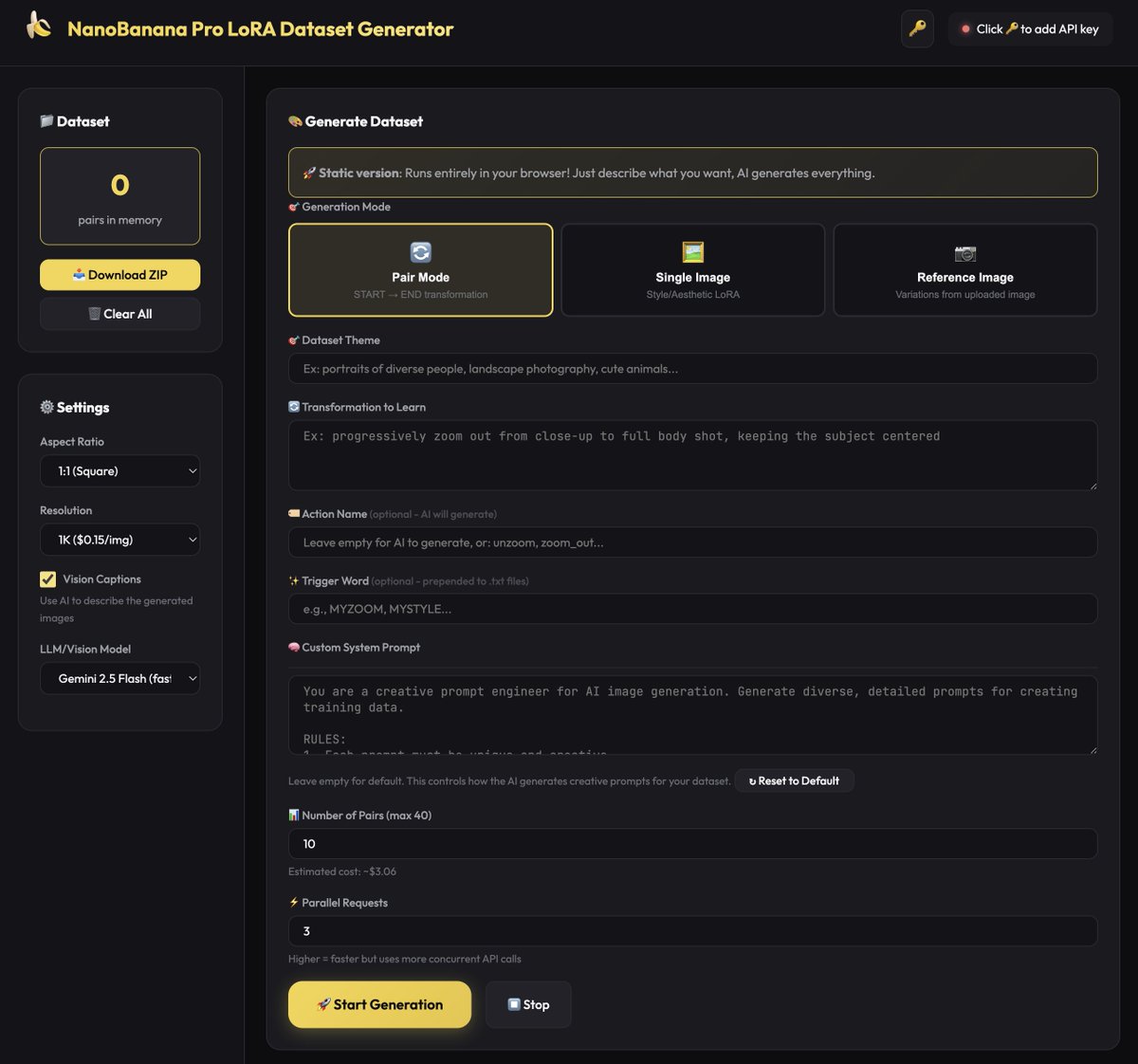
Update to NanoBanana Pro LoRA Dataset Generator!
added 3 new modes:
🖼️ Single Image - Style/aesthetic LoRAs without before/after
📷 Reference Image - Upload a character/product, get variations
🧠 Custom System Prompt - Full control over AI prompt generation
Still 100% browser-based with @fal API ⚡
Perfect for:Z-Image style LoRAs
Character consistency training
Product variation datasets
Any custom aesthetic
🔗 Try it: https://t.co/6ZqotEYhQz
💻 Code: https://t.co/Ko9Zn19eUD

20.0K
353
35
43
3mo ago
OdinLovis
4 billions years - part 1 , made in 2hours with Seedance 2.0 on @fal using api . Semi-automatic process vibe-coded.
Monday I will share the full video and a tutorial on how to make this yourself !
Look at the end if you want to see Dinosaur !
I will show also how to do calibration of lighting etc..
Lovis Odin (@odinlovis) X Stats & Analytics
Lovis Odin (@odinlovis) has 9.11K X followers with a 1.08% engagement rate over the past 12 months. Across 585 posts, Lovis Odin received 17.3K total likes and 1.70M impressions, averaging 29.5 likes per post. This page tracks Lovis Odin's performance metrics, top content, and engagement trends — updated daily.
Lovis Odin (@odinlovis) X Analytics FAQ
How many X (Twitter) followers does Lovis Odin have?+
Lovis Odin (@odinlovis) has 9.11K X (Twitter) followers as of July 2026.
What is Lovis Odin's X (Twitter) engagement rate?+
Lovis Odin's X (Twitter) engagement rate is 1.08% over the last 12 months, based on 585 posts.
How many likes does Lovis Odin get on X (Twitter)?+
Lovis Odin received 17.3K total likes across 585 posts in the last 12 months, averaging 29.5 likes per post.
How many X (Twitter) impressions does Lovis Odin get?+
Lovis Odin's X (Twitter) content generated 1.70M total impressions over the last 12 months.